我们对外提供的/video/list接口会对某用户下所有的视频列表进行分页查询,而vod_video表是一个具有亿级数据量的大表,任何一个对此表的查询都应该慎重对待。
分布式数据库大表查询的常见问题
vod_video表的schema像这样:
|
|
由于均衡字段vid的存在,vod_video表中的数据得以相对均匀地分布在各个数据节点(dbn)上,当客户端查询select from vod_video order by create_time desc limit n offset m时,QS会向每个dbn发送select from vod_video order by create_time desc limit n+m,也就是说每个dbn节点最多会返回(n+m)条数据,所有返回的数据会在QS再做一次merge sort,如果(n+m)很大,那么merge sort的数据集就会很大,一方面会增加排序时间,另一方面也会使QS的网卡流量瞬间飙升,甚至可能超过最大阈值。
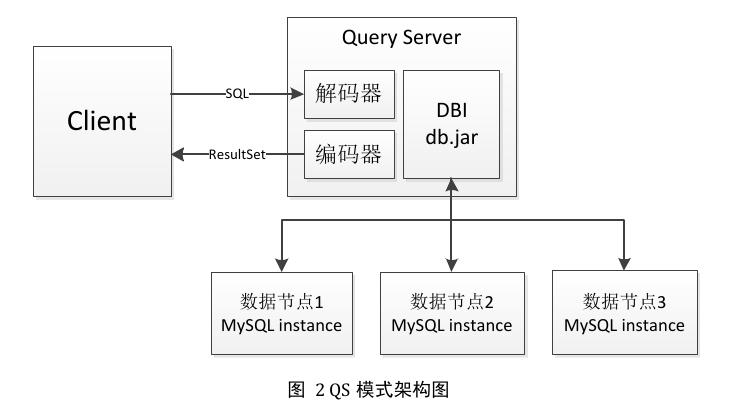
如果按照上面做法,直接将limit n offset m丢给ddb,当用户的查询分页数很大,而且用户下的视频量很大时,每个dbn的返回数量会非常大,严重影响性能。所以需要进行优化。
下面说明优化后的做法。
跳跃式查询
假设有个查询场景,用户查的offset是3万,limit是500,为避免offset过大,我们先查3次,每次的offset是1万limit是1,定位到3万offset的起始位置,然后把这个起始位置带到where条件里面再查下面的500条,如下图所示(图中v1~v30500按视频创建时间create_time降序排列)
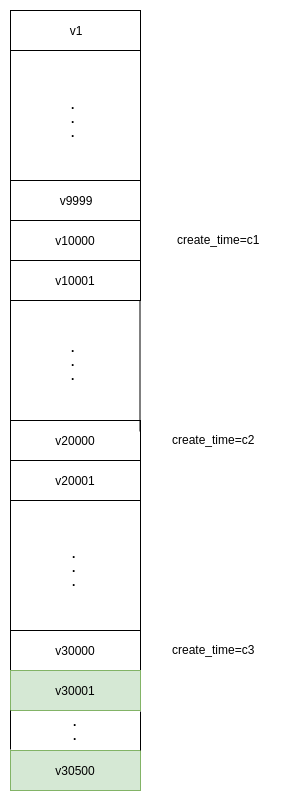
我们的目标是拿到v30001~v30500的数据。
- 首先,select vid, create_time from vod_video where create_time<=32503651200000 limit 1 offset 9999拿到v10000;
- 然后,select vid, create_time from vod_video where create_time<=c1 limit 1 offset 10000拿到v20000;
- 接着,select vid, create_time from vod_video where create_time<=c2 limit 1 offset 10000拿到v30000;
- 最后,select * from vod_video where create_time<=c3 limit 500 offset 1拿到v30001~v30500
这其实是利用了create_time进行跳跃式查询,逐渐逼近v30000,最后再一次取出目标数据。每次查询的offset都不超过10000,不会出现offset过大导致的查询性能下降以及QS网卡流量过大的问题。
当然,这种方法有一个小瑕疵,就是如果有create_time相等的视频,那么每次分页取出的视频可能会有少部分重叠。一方面,create_time是毫秒级别的,所以这种情况产生的概率比较小;另一方面,这种情况其实也相当于是为了提升查询效率的一个tradeoff,在概率较小的情况下是可以接受的,而且用户也可以做一次根据vid的去重来处理这种情况。
